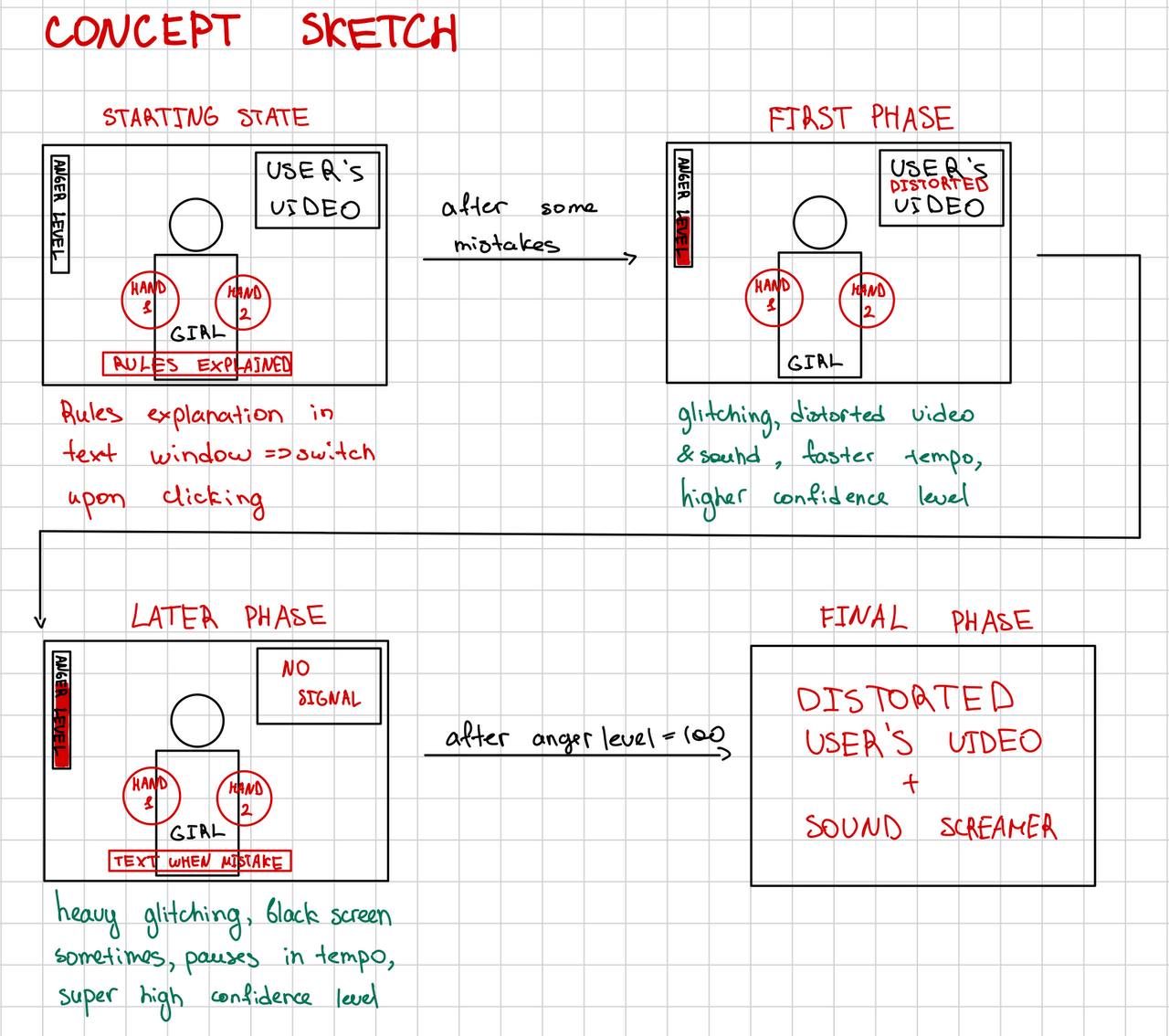
Midterm Idea:
I was inspired by Portal 2 by Valve in this endeavour, with my own twist on the gameplay and concept.
While I haven’t settled on a fitting name thus far for the project, the concept entails a “multi-faceted” reality, with a ray-gun that fires a bullet. When this bullet is incident on specific “panels” in the game, it may reflect off the surface of the panel. The objective is to reflect the bullet such that it reaches a designated mechanism to progress to the next level or finish the game.
The Twist:
This gets interesting in such that there are two realities that this special ray-gun, bullet and panels engage with. That is, the ray-gun may fire bullets in either one of Dimension ‘A’ or Dimension ‘B’. If the panel is of the same ‘dimension’ as the bullet, it will hit the panel and shatter it (this may unlock new areas or cause a loss if the wrong panel is destroyed). Alternatively, if the panel and the bullet differ in their ‘dimension’, then the bullet reflects off the panel and this can then be further reflected off other panel as the concept graphics below show:
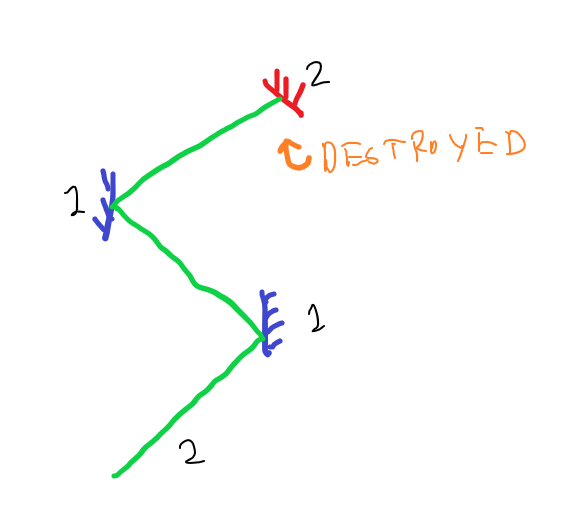
The game will feature inspiration from very simple brutalist architecture, with 1K PBR Textures because I like a degree of realism in my games. Maps will generally be dimly lit, and there will be cool snippets of lore that players can find as they explore different parts of the map or progress though the game.
User Interaction:
Other than the aforementioned ray-gun, there will be WASD keys for forward-backward and left-right movement. Additionally, to look around them, users can drag their mouse towards the sides of the screen to pan their camera. Users can walk to all accessible parts of the map, which will be made sufficiently obvious to avoid confusion, as I am intending on using a darker theme for this game.
Users may use E to fire a bullet, and Q to switch the dimension setting of the ray-gun, id est the dimension of the bullet it fires.
Progression:
There are a total of two levels I plan to implement, and users are limited to three shots from their ray-gun before they have to restart the ENTIRE game because I want to convey a feeling of greater loss, not just that they spawn back at their current level.
Development & Implementation:
I have thus far coded in a very simple game engine to handle all objects. I am going to implement physics and collisions soon, along with more textures and the map.
There are many classes in this, but the two I shall focus on here are ‘BasePart’, which handles a simple 3D box or part of the map in the game, and ‘Workspace’, which is a class that contains all BasePart and other extended instances in the game, as well as contains the camera that displays the map to the user.
Major Concerns and What I’m Dreading:
This projects may seem overly ambitious, but the initial game engine setup has come through nicely. I am not looking forward to collision handling since that always is a nightmare.
Code and Credits:
Find here a link to my code: https://editor.p5js.org/rk5260/sketches/b6B9BVyoE
All code is written by myself (exception below), with many elements I first learnt how to use from the p5.js documentation, after which I implemented them myself.
Exception: The code for the PBR shaders was composed and modified from multiple existing shaders on github and p5.js documentation itself.
All PBR textures sources are credited in a credits.txt file in the PBR Texture’s directory. (Thus far its only GravelConcrete).