Hey everyone, welcome back from your break! 👋
(I know, I know, I wish it was longer too… but hope you had a relaxing and wonderful break!)
This week’s practical assignment was to create a creative/unusual switch. I immediately got a few ideas in my head, but the one I ended up going with, was a “looking at” detector! (or rather, a very crude head rotation detector 😅). I wanted to activate something something just by looking at / facing it.
So I built a simple circuit with 3 LEDs, that could indicate the rotation of my head (where I was facing). I now remember that initially, I also wanted to extend this concept by having a multiple screen setup, and then automatically closing or blacking out the screens I wasn’t facing towards, saving energy. I also had one where it would automatically dispense food or something when I turned my head, building the ultimate “automated-eating-while-working-solution” (which would probably result in a montage of hilarious fails too) 😂. However, I somehow totally forgot about these, and only remembered while writing this blog post right now (and it’s too late to implement them now, probably for the better 😅). But argh man, those would have made for a much more interesting blog :/… oh well.
# Implementation
I first started by connecting 3 LEDs on a breadboard, to 3 resistors which connect to the Arduino’s 3.3V. Then I realised that I could use just 1 resistor, and so wired 3.3V to the resistor, and the resistor to the positive rail of the breadboard. Then I had a wire for each LED’s cathode (the shorter pin, the one that connects to ground), and could now activate any individual LED by connecting the Arduino’s ground wire to the LED’s ground wire! All that was left now was the simply connect ground to a hat (with some tape and foil) and a flag sticking out, and have a foil flag/square for each LED, and success!
This circuit is so simple in fact, that it doesn’t even need the Arduino! Literally the only thing the Arduino is doing here is providing power, which can easily be replaced with a battery. However, when I looked at the requirements again, it says we have to use digitalRead :/… Ah man, ok I’ll need to integrate it.
At first I really wanted to keep the simplicity as much as I could, and basically just try the Arduino pins as ground, so there would be almost no difference in the circuit, but we could detect which LED is being lit up. Unfortunately, I read that this is quite a bad idea as the Arduino isn’t well suited for that, so I had to double the number of wires, to separate the switch part from the lighting part. The circuit now still works in a very similar way, it’s just that when I try now connect 2 wires (meaning my head has turned to a certain position), the Arduino detects the switch is activated, and then powers the corresponding LED. Same functionality, but with including the Arduino and its digitalRead and digitalWrite functions. Oh also, I used “INPUT_PULLUP” instead of “INPUT” for the pinMode, as I didn’t want to add another 3 resistors 😅 (so the readings are flipped (as there’s no “INPUT_PULLDOWN” on most of the Arduino boards), 1 for inactive and 0 for active, but this isn’t an issue).
Code:
const int rightLED = 10;
const int centerLED = 11;
const int leftLED = 12;
const int rightSwitch = A0;
const int centerSwitch = A1;
const int leftSwitch = A2;
void setup() {
// Initialize serial communication at 9600 bits per second:
Serial.begin(9600);
// Inputs (set to INPUT_PULLUP instead of INPUT so that it automatically pulls up the value, saving me from adding 3 resistors 😅)
pinMode(rightSwitch, INPUT_PULLUP);
pinMode(centerSwitch, INPUT_PULLUP);
pinMode(leftSwitch, INPUT_PULLUP);
// Outputs
pinMode(rightLED, OUTPUT);
pinMode(centerLED, OUTPUT);
pinMode(leftLED, OUTPUT);
}
void loop() {
// Read the input pins
int rightState = digitalRead(rightSwitch);
int centerState = digitalRead(centerSwitch);
int leftState = digitalRead(leftSwitch);
// Power the correct LED
digitalWrite(rightLED, rightState == 0 ? HIGH : LOW)
digitalWrite(centerLED, centerState == 0 ? HIGH : LOW)
digitalWrite(leftLED, leftState == 0 ? HIGH : LOW)
// Print out the states
Serial.print(rightState);
Serial.print(',');
Serial.print(centerState);
Serial.print(',');
Serial.println(leftState);
delay(1); // Short delay between reads for stability
}
# Final Result
# Additional Thoughts & Room for Improvement
I initially wanted to use a potentiometer, to be able to get a much greater resolution and more accurately determine where the head was facing (and hence, have more fine grained control over what activates), while also eliminating a few wires and the need to have the foil flags. While I opted out of that idea as this assignments requires we use digitalRead, it would be a great improvement.
Well, unfortunately that’s it for today (yea, this was a very short blog), so until next time!
Update: Fixed the link, as it turns out, it was broken this entire time!
(wait, so you’re telling me that no one got to play my game? 🙁)
# Introduction & Project Concept
Hey everyone, welcome back! 👋
In this blog, I’ll be talking a little bit about my midterm project. Unfortunately (or fortunately, depending on how much you want them), this blog post isn’t going to be as detailed as my usual ones. Instead, it’ll just be a very cursory overview of a few parts of the project.
So, what is my project? Well, it’s a game where you control a character using your own body (pose detection), and you have to try to fit through the target pose cutouts, similar to the ones you see in cartoons when a character goes through a wall.
Though, since the poses are detected using a webcam, it can be hard to get the distance and space required to detect the whole body (and also still clearly see the screen), so instead the cutouts are only for the upper body, which should make it accessible to and playable by more people.
# Implementation Details
## How it Works (in a Nutshell)
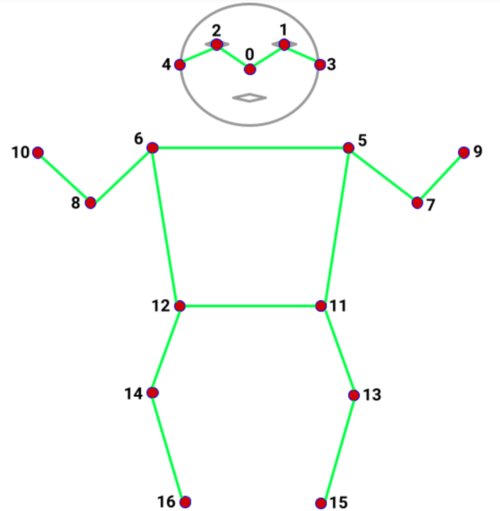
The core mechanic of the game is the player’s pose. Thankfully, this can be detected relatively easily with the help of ml5.js’s BodyPose, which after integrating, lets you know the locations of each of the keypoints. From the 2 models available (Movenet and BlazePose), I choose Movenet, and you can see the the keypoints it detects below.
Obviously, the keypoints the camera can’t see won’t be very accurate at all, but the model will still report them. Thankfully, it also reports its confidence, and so you can easily filter out the keypoints which don’t have a certain threshold confidence.
In terms of why I choose MoveNet, it’s because it is the newer model, and was built for faster recognition, which is important in a game like mine (you obviously don’t want players to notice or feel a lag in their movements, which makes it harder to control and less enjoyable) (though to be honest, BlazePose would work fine here too, it would just be a bit slower and laggier). Also, another one of the parameters I specified was the type (SINGLEPOSE_THUNDER), which means that it should only track 1 person, and with slightly higher accuracy.
Anyways, so we got our pose, and I drew it on the screen. Then, the player sees a target pose cutout (which was generated by creating a random pose, and erasing those pixels from the surface), and tries to match it (hopefully, you don’t wanna crash into it!). Once the target is close enough, we check if the player’s pose matches the target cutout’s pose. Now, since it’s nearly (or literally) impossible to match it exactly to the subpixel (in this case, 13 decimal places smaller than a pixel!), especially for every point, we just check whether the pose’s are close enough, by adding a bit of margin to point and checking if the keypoints are within that margin. If it matches, hurray! The player scores a point and the target disappears (only for another one to come out later… 😈, ahem 😇). Otherwise, the target still disappears, but instead of scoring a point, they lose a heart/life. If they’ve lost too many, the game ends.
That basically sums up the main game loop.
Now, this is all implemented in an OOP manner, so there are classes for each scene, and for any objects that would benefit from being a class. So, for scene management, I have an object/dictionary containing a reference to all the scene objects instantiated from their respective classes, and field that holds a reference to the current scene (or alternatively a variable that keeps track of the current scene’s name).
Similarly, I also have an object/dictionary containing all the sounds and images to be used (which get loaded in preload, like the pose detection model). Other than that, the rest is mostly similar to other p5.js projects.
## Some Stuff I Liked
This may seem small, but one of the parts I like is my random pose generation. Since it is, you know, a core part of the gameplay (the pose for the target cutouts), I had to get this done fairly well. While I initially thought of using random offsets from a set pose, or even a set of custom poses I did (which would save a lot of time), I knew this solution wouldn’t be the best, and would have several issues (for example, others will likely have a different height and body segment lengths, as well as from different distances and angles to the camera). Instead, my current solution accounts for most of that, and is made it from a system of constraints.
Basically, I first measure some key lengths from the player (such as the distance between the wrist and the elbow, elbow to the shoulder, shoulder to the hip, original y-value of nose, etc). Then I first start by generating random coordinates for the nose, which are in the center 25% (horizontally) of the screen, and within 25px or so (vertically) of the player’s original nose height (btw, so instead of generating several points for the head (eyes, ears, & nose), like the model outputs, I can just treat the nose as the center of the head, which is much simpler and surprisingly doesn’t have almost any drawback for my usecase, so I do that). After this, I get a random angle between -30 to 30 degrees for the shoulder midpoint, and then calculate the shoulders from there (taking into account the player’s shoulder to shoulder length, and nose to shoulder midpoint length). Similarly, I also calculate a random angle in a certain acceptable range, and use the user’s segment length to calculate the exact position. Now, I also want to ensure that no part goes offscreen, or even within 10% of the edges, so I wrap the generation of each part in a do… while loop, which ensures that if a certain part does get generated too close to the edge, it tries again, calculating new positions from new random but constrained values. Additionally, I also don’t want any of the points to be too close to each other (which could especially be an issue with the wrists, both to each other and to the head).
But what if it is literally impossible to satisfy all these constraints for a certain part? Then the program will just keep trying and trying again, forever, which we obviously don’t want. So I keep a track of the number of current attempts, and if it goes above a certain threshold (say 10), then I start from scratch, and return a completely brand new random pose, using recursion (hoping that the new system won’t run into similar situations too many times, which thankfully is the case, as it’s quite rare for it to retry). I also keep a track of the number of attempts for the completely new pose, and if it gets too high, then I just return the default pose (this is more so just to be extra safe, since thankfully, this is almost never going to happen, as there is an extreeeemeeellyyyy small chance that it bails out and fails trying to return a completely new pose, that many times).
So, that’s it! Despite being really quite simple, it’s pretty effective. You can see the code for it, and try it out in the sketch, below (it’s actually a bit unnerving and intriguing how we can associate actions and feelings, just by looking at random poses made with simple rules).
// Initialised with some default values (roughly my measurements)
let playerBodyInfo = {
"nose y-value": 165,
"nose-shoulder midpoint length": 50,
"shoulder midpoint-hip midpoint length": 150,
"shoulder-shoulder length": 90,
"shoulder-elbow length": 70,
"elbow-wrist length": 60
}
// lots of other code ... (not relevant for this)
// method within Game class
generateRandomPose(attempts = 0) {
// Constraints / Ideas / Assumptions:
// - Nose should be in the middle 25% (horizontally) of the screen, and near the height of the player's nose originally (similar y-value)
// - 0 deg <= midpoint-shoulder-elbow angle (inside one) <= 180 deg (basically, the elbow should be outside the body, extending upwards)
// - 45 deg <= shoulder-elbow-wrist angle (inside one) <= 180 deg
// - All parts should be within the center 80% (the nose and shoulders don't need to be tested, since they can't reach there anyways)
// - Also, parts shouldn't be too close to each other (realistically the thing we need to check for is wrists to each other and the nose)
// - First generate nose position (center of head), then shoulders, then so on.
let outerMargin = 0.1; // 10%, so points should be in the middle 80% of the detection area (webcam feed)
let minX = webcamVideo.width * outerMargin
let maxX = webcamVideo.width * (1 - outerMargin)
let minY = webcamVideo.height * outerMargin
let maxY = webcamVideo.height * (1 - outerMargin)
let partAttempts, leftShoulderToElbowAngle, rightShoulderToElbowAngle, leftElbowToWristAngle, rightElbowToWristAngle
// Initialised with some default values (roughly my measurements)
let pose = {
nose: {x: 320, y: 165},
left_shoulder: {x: 275, y: 215},
right_shoulder: {x: 365, y: 215},
left_hip: {x: 295, y: 365},
right_hip: {x: 345, y: 365},
left_elbow: {x: 220, y: 255},
right_elbow: {x: 420, y: 255},
left_wrist: {x: 200, y: 200},
right_wrist: {x: 440, y: 200}
}
// If it takes too many attempts to generate a pose, just give up and output the default pose
if (attempts > 100) {
print('Pose generation took too many attempts, returning default pose.')
return pose
}
// Nose
pose.nose.x = random(0.375, 0.625) * webcamVideo.width // center 25%
pose.nose.y = random(-25, 25) + playerBodyInfo["nose y-value"] // y-value +- 25px of player's nose height
// Shoulders
let shoulderAngle = random(-PI/6, PI/6) // The angle from the nose to the shoulder's midpoint with origin below (think of a unit circle, but rotated clockwise 90 deg) (also equivalently, the angle from the left to right shoulder, on a normal unit circle). From -30 to 30 degrees
let shoulderMidpoint = {
x: pose.nose.x + sin(shoulderAngle) * playerBodyInfo["nose-shoulder midpoint length"],
y: pose.nose.y + cos(shoulderAngle) * playerBodyInfo["nose-shoulder midpoint length"]
}
pose.left_shoulder.x = shoulderMidpoint.x - cos(shoulderAngle) * 0.5 * playerBodyInfo["shoulder-shoulder length"]
pose.left_shoulder.y = shoulderMidpoint.y + sin(shoulderAngle) * 0.5 * playerBodyInfo["shoulder-shoulder length"]
pose.right_shoulder.x = shoulderMidpoint.x + cos(shoulderAngle) * 0.5 * playerBodyInfo["shoulder-shoulder length"]
pose.right_shoulder.y = shoulderMidpoint.y - sin(shoulderAngle) * 0.5 * playerBodyInfo["shoulder-shoulder length"]
// Hips
let hipMidpoint = { // The hip's midpoint is really just the shoulder's midpoint, but extended further, so we can calculate it in a similar fashion
x: pose.nose.x + sin(shoulderAngle) * (playerBodyInfo["nose-shoulder midpoint length"] + playerBodyInfo["shoulder midpoint-hip midpoint length"] + 50*0), // [Nvm, disabled for now] Added 50 in the end, to ensure it's long enough (I'm not using the hips for accuracy or points, but rather just to draw the outline)
y: pose.nose.y + cos(shoulderAngle) * (playerBodyInfo["nose-shoulder midpoint length"] + playerBodyInfo["shoulder midpoint-hip midpoint length"] + 50*0) // (as above ^)
}
pose.left_hip.x = hipMidpoint.x - cos(shoulderAngle) * 0.5 * playerBodyInfo["shoulder-shoulder length"]
pose.left_hip.y = hipMidpoint.y + sin(shoulderAngle) * 0.5 * playerBodyInfo["shoulder-shoulder length"]
pose.right_hip.x = hipMidpoint.x + cos(shoulderAngle) * 0.5 * playerBodyInfo["shoulder-shoulder length"]
pose.right_hip.y = hipMidpoint.y - sin(shoulderAngle) * 0.5 * playerBodyInfo["shoulder-shoulder length"]
// Elbows
partAttempts = 0;
do {
if (++partAttempts > 10) return this.generateRandomPose(attempts + 1); // If it takes too many attempts to generate this part, just give up and start from scratch
leftShoulderToElbowAngle = random(PI/2, 3 * PI/2) + shoulderAngle // From 90 to 270 (-90) degrees on a normal unit circle (basically 0 to 180 degrees, with the left half of a circle (imagine the unit circle rotated anticlockwise 90 deg))
pose.left_elbow.x = pose.left_shoulder.x + cos(leftShoulderToElbowAngle) * playerBodyInfo["shoulder-elbow length"]
pose.left_elbow.y = pose.left_shoulder.y - sin(leftShoulderToElbowAngle) * playerBodyInfo["shoulder-elbow length"]
} while (
minX > pose.left_elbow.x || pose.left_elbow.x > maxX || // Check if it's within the acceptable horizontal range
minY > pose.left_elbow.y || pose.left_elbow.y > maxY // Check if it's within the acceptable verticle range
);
partAttempts = 0;
do {
if (++partAttempts > 10) return this.generateRandomPose(attempts + 1); // If it takes too many attempts to generate this part, just give up and start from scratch
rightShoulderToElbowAngle = random(-PI/2, PI/2) + shoulderAngle // From 270 (-90) to 90 degrees on a normal unit circle (basically 0 to 180 degrees, with the right half of a circle)
pose.right_elbow.x = pose.right_shoulder.x + cos(rightShoulderToElbowAngle) * playerBodyInfo["shoulder-elbow length"]
pose.right_elbow.y = pose.right_shoulder.y - sin(rightShoulderToElbowAngle) * playerBodyInfo["shoulder-elbow length"]
} while (
minX > pose.right_elbow.x || pose.right_elbow.x > maxX || // Check if it's within the acceptable horizontal range
minY > pose.right_elbow.y || pose.right_elbow.y > maxY // Check if it's within the acceptable verticle range
);
// Wrists
partAttempts = 0;
do {
if (++partAttempts > 10) return this.generateRandomPose(attempts + 1); // If it takes too many attempts to generate this part, just give up and start from scratch
leftElbowToWristAngle = random(1.25*PI, 2*PI) + leftShoulderToElbowAngle // random(PI/4, PI) // From 45 to 180 degrees on a normal unit circle. Will be rotated to account for the elbow's existing rotation
pose.left_wrist.x = pose.left_elbow.x + cos(leftElbowToWristAngle) * playerBodyInfo["elbow-wrist length"]
pose.left_wrist.y = pose.left_elbow.y - sin(leftElbowToWristAngle) * playerBodyInfo["elbow-wrist length"]
} while (
minX > pose.left_wrist.x || pose.left_wrist.x > maxX || // Check if it's within the acceptable horizontal range
minY > pose.left_wrist.y || pose.left_wrist.y > maxY || // Check if it's within the acceptable verticle range
dist(pose.nose.x, pose.nose.y, pose.left_wrist.x, pose.left_wrist.y) < 50 // Check if the wrist is too close to the nose ); partAttempts = 0; do { if (++partAttempts > 10) return this.generateRandomPose(attempts + 1); // If it takes too many attempts to generate this part, just give up and start from scratch
rightElbowToWristAngle = random(0, 3/4 * PI) + rightShoulderToElbowAngle // From 270 (-90) to 90 degrees on a normal unit circle (basically 0 to 180 degrees, with the right half of a circle)
pose.right_wrist.x = pose.right_elbow.x + cos(rightElbowToWristAngle) * playerBodyInfo["elbow-wrist length"]
pose.right_wrist.y = pose.right_elbow.y - sin(rightElbowToWristAngle) * playerBodyInfo["elbow-wrist length"]
} while (
minX > pose.right_wrist.x || pose.right_wrist.x > maxX || // Check if it's within the acceptable horizontal range
minY > pose.right_wrist.y || pose.right_wrist.y > maxY || // Check if it's within the acceptable verticle range
dist(pose.nose.x, pose.nose.y, pose.right_wrist.x, pose.right_wrist.y) < 50 || // Check if the wrist is too close to the nose
dist(pose.left_wrist.x, pose.left_wrist.y, pose.right_wrist.x, pose.right_wrist.y) < 50 // Check if the wrist is too close to the other wrist
);
return pose;
}
(Click inside the sketch, then press any key to generate a new random pose)
Another part I liked was the illusion of perspective. So basically, I had to rush this project, so I thought, “Fine, I’ll do it in 2D, that’s much simpler”, and it is, but I still wanted that 3D perspective effect 😅. After playing around for a bit in a new temporary sketch, I found out that if I scale everything from the center, then the 2D sketch appears to have (a very basic, rudimentary, and probably physically inaccurate, but nonetheless, visible) perspective! While the best and fully implemented version is in the final game, you can see that temporary sketch below.
(Click inside the sketch, then press r to restart, or any other key to toggle between the first and second test (now basically just uncoloured vs coloured)… oh also, please, you know what I mean by “any other key”, so don’t press the power button or something 😂)
## Some Issues I Encountered
Oh boy oh boy, did I face several issues (as expected). Now, I can’t go over every issue I faced, so I’ll just mention a couple.
First one I’ll mention, is actually the random pose generator mentioned above! Yep, while I did end up getting it working (and well enough that I liked it and included it in my good parts section), and while it is conceptually pretty simple, it still took a fair bit of time (wayy longer than I thought it would, or even still think it needs to), and was a bit tricky, particularly with working out the angles and correct sin and cos transformations (oh, I messed up the signs more than once 😅). In fact, I actually made the sketch above to quickly test out my pose generation! I had written it all “blind” (aka without testing in between), and since it was fairly straightforward, I was confident it would work, but something nagged me to just try it once before the seeing it in the main game, and… yep, it didn’t work. *sighs*. I had to meticulously comment out and retry each portion and work back to a full solution, bit by bit. Fortunately it wasn’t too conceptually difficult (more time consuming than hard, but even the basic trig was a little rough tough at 3 AM), so I succeeded.
Another issue I faced was that the target cutouts, didn’t have any actual cutouts(!), which is, you know, a major issue. Again, I broke out a new temporary sketch to test out my logic, simplifying stuff and working things out. It turned out to be a simple issue of using the screen’s width instead of the webcam’s width, and a few other things. In case you’re wondering, yep, the screen and webcam not only have different resolutions, but also different aspect ratios! It was a bit of a pain initially to get it so they worked seamlessly together, but now I have. The reason behind this, is that some webcams (particularly those on laptops) give a 4:3 image for some reason, and since I need to run a machine learning model (MoveNet, for the poses), they usually reduce the resolution required (otherwise it would take a LOT longer to detect the pose, which would break the game). I wanted the game’s output on the other hand to be a crisp (scalable up or down but ideally) 1920×1080, 16:9 aspect ratio, hence the mismatch.
(It’s not really interactive (besides f for fullscreen), so don’t bother ;) )
Well anyways, that’s it for now (I think I might’ve made it a bit longer and more detailed than originally thought 😅), so without further ado, I present, my ✨midterm project✨! (I should really have a name for it, but I can’t decide 🤦♂️)
# Final Result – Midterm Project
While I would normally embed the sketch here, I think you should really open it full screen in a new tab, so follow this link.
# Additional Thoughts & Room for Improvement
With any project, there’s always room for improvement. But for this one specifically, there’s a huge room for improvement 😅 (mainly because I keep seeing new features to implement or ideas to improve it). As usual, there are a bunch of things I didn’t get time to implement or do, ranging from better graphics and polish, to levels and features. I particularly wanted to implement a character that actually goes ahead of you (that you are trying to catch) that “breaks” the walls (causes the cutouts), and also a level that took place in a top secret laboratory setting, where the character is actually stealing some top sneaky info, and so you have to stop them. I kind of really want to continue this and flesh it out (but I also know it’ll not be of much use, and besides, p5 isn’t the best platform to implement this idea, so why waste time here… so anyways *cuts to me working on this months into the future* 😅). Well, I’m really glad you went through the entire post (and definitely didn’t skip till the final result), but regardless, thanks a lot for reading it (does anyone even read these, or am I just talking to myself? ._. ). Unfortunately, that’s all I’ve got time for, so we’ll have to end it here. Until next time, and enjoy your break!
(psst, do you know what time his watch shows? Ok, fine, it isn’t wearing one, but if it did, it would show)
Like probably everyone else on the entire planet, I wasn’t really sure what to do for my Intro to IM Midterm Project at NYUAD (ok fine, maybe not everyone else) (fun fact, I’m still not certain 😂😭). I was deliberating whether to stick with traditional input devices (mouse and keyboard), or go for some interesting new (like the classic and probably cliche, face or body tracking). Unfortunately, I don’t own a guitar like Pi Ko, so I guess I’ll have to stick with something traditional 😅 (now that I think about it, I could use a piano, wait a moment…)
# Piano Game Concept
A piano game concept!… Gosh… why do I waste so much time, on a joke concept…
So the keys of the piano (but optionally also the keyboard, allowing everyone to play it) control the height of the bars, and you have to get a ball that drops out of the start area into the goal, potentially avoiding obstacles and overcoming bad physics, all the while automatically producing (probably ear piercing) musicrandom garble of sounds. That’s a win-win-win!
Ok, this was a joke. Now back to the actual concept I wanted to talk about 😅 (though to be honest, this seems more original and fun ._.)
# Actual Game Concept
You know those outlines they have of people (like at crime scenes, but don’t think about that)?
Or those ones where a cartoon character goes through a wall?
Well, what if you had to make the correct pose to fit through a series of holes and avoid hitting the wall? That’s the essence of my idea. I thought about it while thinking on how I could utilise face/body tracking (which probably shows 😅), and which is exactly the wrong approach (you’re supposed to first have an issue/idea, then think about how to solve it, not try to find a use case for a certain techonology, that’s like a solution in search of a problem). Also, this idea is simple and obvious enough that while I haven’t seen it yet, it very well might already be a real thing. Still, I find the idea quite charming, especially as I envision it on a large screen, with people frantically and hilariously jumping around positions. I will also include a “laptop mode”, where the program only shows upper body cutouts, in order to make it accessible and playable on laptops too (where it would be hard to get the distance required for the camera to see the full body, while still allowing you to comfortably see the screen).
It should not come as a surprise then, that I plan to use body tracking to be able to control the motion of the character. Of course, it would be a gargantuan task to implement a decent body tracking solution from scratch (something more for a final year’s or even PhD’s research project than an Intro to IM midterm), so I will use a pre-existing library to handle the detection for me, mainly movenet (probably through ml5.js), a fast and accurate pose detection model by Google.
As I was thinking about this a bit, I began thinking that maybe this could be about a ninja’s training. You enter the secret facility (the interface is hopefully interactable through hand gestures, similar to the Xbox with kinect, if I have enough time), and then have to undergo the “lightning quick attack & defense poses” (or something), as part of your training.
## Complex part & Risk Reduction
As part of our midterm progress blog post, we have to identify the most complex/frightening part, and do something to tackle and reduce that risk. For this project, it is obviously the body tracking, so I created a new sketch to test out the library, and coded together a simple barebones concept to ensure the tracking works, and if I can reliably assess whether a person is in the correct pose. In addition to the pose detection, it also displays a skeleton of the person (of the detected points), and I made it slightly show the webcam’s video feed (both to help the player adjust their position). Also, it shows a (faint) guide to the target pose.
Mini rant:
I first made an image for the target pose, but I’m still somehow unable to upload anything to p5, despite trying with different browsers, at different times, and even different accounts, since the start of the semester (yep, I haven’t been able to upload anything at all). Luckily in this case, it was just a simple image, so I drew it manually with p5.js (which is better in fact, since the image automatically updates if I change the target pose), but still, this is extremely annoying and limiting. If you know any solutions, please let me know.
Try and see if you can match the pose!
(Hint: It tests for the shoulders, elbows, and wrists. Also, try moving back and forth if the frame doesn’t fit, and try changing the lighting if it isn’t detecting you properly (ignore the flickering, that’s a known issue))
It works! Something I don’t like is the constant flickering, but I think I might be able to mostly solve that (at the expense of slower update times, by using a moving/sliding average), so I would consider this a success!
I was reading this great article about Computer Vision for Artists and Designers, which mainly talks a bit about the history of computer vision, interactive media using computer vision, and some basic computer vision techniques.
It made me think about an interesting comparison, of the difference between our vision, and that of a computer’s. While the structural and architectural differences are obvious (biological vs technological), a more interesting comparison point lies in the processing. Video, as the article mentioned, doesn’t contain any inherent, easily understood meanings. Instead, in both cases, it is up to the processing to extract key information and figure out the required details. While such a task is usually easy for our brain, trivial in fact, is an incredibly difficult problem to overcome, especially from scratch. It might seem easy to us, because our brain is one the most complex things in the universe, and also had a huge head start 😂, allowing it to develop specialised pathways and processes capable of carrying out this operation in a breeze, which is understandable as vision is an extremely important tool in our survival. Computer vision meanwhile, is starting in this gauntlet of a task, nearly from scratch. While we do not have to evolve biological structures and compete on our survival, there is still a very real challenge, though thankfully, we can progress on this frontier much quicker than evolution or nature could (that big brain of ours coming in handy again. Wait, if you think about it, we are using our eyes and brain, to replace, our eyes and brain… and our entire body and self, in fact).
There are several methods of implementing different aspects of computer visions. Some basic ones, mentioned in the article, include detecting motion (by comparing the difference in the current frame with the previous one), detecting presence (by comparing the difference in the current frame with one of the background), brightness thresholding (just checking if a pixel is lighter or darker than a certain threshold), and rudimentary object tracking (usually by finding the brightest pixel in the frame), though many other basic techniques also exist (eg. such as recognising what a picture is by comparing against a stored collection of images). These basic implementations however cannot stand much alternation in their expected environment, and even something relatively simple (like the background changing colour, perhaps by a shadow being cast) would render them ineffective. Also, trying to implement a task as vast as computer vision by precise, human defined algorithms, is extremely hard (I know all algorithms are technically precisely defined, so what I mean by this is that we have specifically coded in behaviours and processes).
A far more successful approach (like in many other fields from aerodynamics to energy efficiency), has been to try and somewhat copy what nature does (though on a simpler scale). “Recent” approaches like neural networks, and other machine learning techniques, have begun far outperforming anything a precisely defined algorithm could do, on most real world tasks. The simplest structure of a neural network, is to have neurones, or nodes, connected to other nodes, and the value is simply modified as it travels from node to node (vast oversimplifying), mimicking the model of the neurons in a brain (though in a much more basic representation). The beauty of such approaches is that they leave the specifics undefined, allowing the model and training process to improve itself, automatically choosing a somewhat good selection of processes to extract meaningful information (when done right). Of course, this doesn’t mean that this is easy, or that one a neural network is made, all the problems can be solved by simply feeding it enough data – innovation in the architecture of the neural networks themselves (e.g. the introduction of U-nets, LTSM, transformers, etc) and surrounding ecosystem must also happen – but it does allow a different way of doing things, which has so far yielded fruitful results (checkout any of the vast number of computer vision libraries, including PoseNet, YOLO, and probably most importantly, OpenCV).
Though the advancements in computer vision are coming ever faster, and many people around the globe dream about being able to control things with just their body and vision (probably in no small part due to movies showing cool futuristic tech), the use of computer vision, in anything, is still a heated discussion. On one hand, widely implementing it could provide alternative pathways to accomplish tasks for many people who might otherwise not be able to do it, increasing accessibility, and it also enables several use cases which before were never even thought to be remotely possible (and also, it’s just cool!). On the other hand however, as with any technology, we have to acknowledge that the vast capabilities of such a system could also be used for nefarious purposes. In fact, governments and corporations are already misusing the capabilities to carry out dystopian practices on an unprecedented scale, widely being in mass surveillance, targeted tracking, selling user info, avoiding responsibilites (eg. car manufacturers on warranty claims), and so much more, all for power and profit (you might think I’m exaggerating a little, but no, look it up. The rabbit hole goes extremely deep (and I’d be happy to chat about it 🙂 )). As a certain spidey’s uncle once said, “With great power comes great responsibility”, and currently, we can’t be sure that those with that power won’t abuse it, especially as they have already routinely been.
With such a conundrum of implications and possibilities, computer vision’s use in interactive art is no doubt a little damper, with it predominantly being featured in places where it is easily and visibly stopped/escaped, such as galleries and public (but not too public) and private installations, and apps and websites users trust, vs throughout every aspect of our lives (though it is undoubtedly hard to fully trust an app/website, and that trust can be easily broken, though of course, not everyone is as weary of these technologies).
After reading Don Norman’s “The Design of Everyday Things”, I was reminded to take a look around me, and find out other examples of bad user experience. One of the first examples that comes to mind, is from my short time at NYUAD’s dorms. As you can see, there are 2 blinds in the same window, one partially translucent, and one fully opaque.
NYUAD’s blinds
While the mechanism to control a particular blind is simple enough, and a common enough pattern for us to intuitively use it, what is extremely confusing is which string controls which blind, as they are both identical! Also, it seemed liked different windows had a different arrangement/side of strings controlling each blind! My solution to fix this, would be to have the opaque one keep it’s metal beads, but to switch the translucent one’s beads to like a white plastic. This way, you can both see and feel the difference between the 2 strings, allowing you to easily choose which blind to control. Additionally, they can be in any order/side, but it must be consistent for all the windows, allowing you to develop muscle memory.
Another example, though not affecting everyone, is USB. You might think I’m referring to the USB A style connectors, that somehow always take 3 tries to get in.
I didn’t know they exhibited quantum properties!
No, that has mostly been solved with USB C (ah, a godsend). Unfortunately, USB C has introduced it’s own complications, by becoming the universal standard!
Wait, a minute, that doesn’t make sense. Isn’t that a good thing?
Well mostly yes, but this also means that USB C’s capabilities have far expanded outside the original scope of a USB connector, allowing the transfer of not just power and files (each at different levels), but also HDMI, DisplayPort, Thunderbolt, Ethernet, and so much more. The result is an incredibly convenient ecosystem and user experience, where everything fits together seamlessly… as long it works. The issue isn’t USB C’s reliability, but rather that since it supports so many protocols and extensions, almost all of which are optional, it can be quite hard to know which cable or device (or even port on the same device!) supports which features (this could supporting a protocol, like DisplayPort, or a certain power and speed output). As a result, it often leads to frustration, realising only after a long time wondering why it isn’t working, that the cable I have in hand is inadequate for the task.
The solution I would recommend, would be to support everything that makes sense, and the highest speed & power level. Although, of course I would say that, I’m the user! It’s true that going this route is going to considerably increase costs for manufacturers, though as Don Norman said, poor design is sometimes due to decisions aimed at reducing cost, and this is certainly an example of that, so maybe it would be worth it for manufacturers to implement it, at least for our sanity.
Note:
Obviously, the capabilities supported should be within reason. FOr example, it makes no sense for a router which lacks any direct graphical interface, to support HDMI or DisplayPort in their USB C ports. Also, there does exist a standard that supports almost everything, and the best power & speed levels, which makes it much easier to know what works, Thunderbolt . However, it is usually pretty expensive and isn’t offered/supported on many devices. Oh also, USB’s naming needs to be fixed. They have changed it so many times, leading to a massive amount of confusion. Search it up.
Coming to second part of our prompt, I believe the main way we can apply his principles, is by integrating discoverability, affordances, & signifiers, with deliberate thought. Namely, we should make sure that we strive towards adapting our work around the person, having intuitive design, where the user doesn’t need to read an instruction manual (or ideally, read any instructions at all, possibly by using familiar visual elements and design practices people have already gotten accustomed to) to interact with our work. It should instead nudge or guide the user subtly (if required), and perhaps most importantly, provide immediate (and satisfying) feedback, and provide the space for people to make mistakes, but gracefully get back on track.
They should enjoy interacting with our work, not be afraid or overwhelmed by it that, so that it doesn’t end up like the unfortunate (but probably technically great) Italian washer-dryer combo 😉
A sad, abandoned boi, forever waiting for someone to enjoy using it🥺
Chris Crowford’s “The Art of Interactive Design”, was certainly an interesting read. He takes a rather more strict approach to interactivity, perhaps due to the blatant misuse of the word on things undeserving to be called interactive, which in turn potentially makes it more useful, especially as the meaning is easier to grasp. By distilling it into 3 clear parts (listening, thinking, and speaking), it makes it easier for designers to assess where their piece could potentially perform better.
Although it seems a bit controversial, to be honest, I quite agree with his definition, but I can easily see how others might not. Many common forms of interactive media are dismissed by him, but he backs it with a point I liked, a distinction between “interactive” and “intense reaction”, which can so often be blurred.
Another point I really liked was “No Trading Off”. Previously, I would’ve assumed that if 2 parts of his interactive design’s defintion were done really well (while it wouldn’t be the same as all 3 being done well), it would come pretty close. However, he claims this is not the case, and it is a logical thing to believe.
Ultimately, I feel like his definition is most relevant to us in helping us better plan the components of our design, ensuring that it “listens”, “thinks”, and “speaks” well. This is something I could really use, as I often spend too much in the “thinking” and “speaking” part, designing something technically incredible, but ultimately, not as interactive.
One off-topic point, I like his style of writing, as it’s less formal / more personal, which makes it more enjoyable to read (particularly things like his explanation on books & films not being interactive, or the questions).
Earlier in class, the professor showed us the Bloom app (by Brian Eno & Peter Chilvers), which I found really calming & elegant, with its simple and easy to understand function and interface. While thinking about it again at home that day, I remembered a few things I saw a while ago, that mainly related to the music that was coming out. One of them was ProjectJDM‘s videos (most notably his famous rainbow pendulum wave) and CodeCraftedPhysics‘s videos (such as this one). So, for this week’s project, I’d thought it been interesting to try and make something similar to the rainbow pendulum wave, also called, a polyrhymtic spiral (polyrhythm, due to the sound structure, and spiral, due to, it well, making spirals).
# Implementation
To start off, I began by just making some points along a line (plain and simple, without any classes for now).
translate(width/2, height/2)
circle(0, 0, 10) // Center circle, filled (just for reference)
let n = 7 // Number of circles
for (let i = 0; i < n; i++) {
circle(width/15 + i*4*width/(10*n), 0, 10) // Outer dots, outlined
}
I’m just drawing a few circles in a straight line in a loop. The spacing is a bit interesting, as width/15 is the offset from the center, and then the formula i*4*width/(10*n) increments the spacing for each index, mainly by dividing the width by the number of dots (I wrote it as a much simpler but slightly longer equation before, but now I can’t undo it 😅. Besides, I ended up redoing spacing anyways).
The logic for the spacing is as follows. We want points along a line, that have a margin from the center and edges of the screen. So we take the width and subtract a margin * 2 from it. Then we divide up the remaining space by the number of points we want to draw.
Then I changed it to using polar coordinates instead. You should be familiar with polar coordinates and some circle stuff by now (you did read my blog last week right 🤨? It explains some of this), which will come in handy as some of the logic is similar to last week’s work. I position the small circles along larger circles (rings) with differing radii, and then we can move them around in a circle, similar to how we drew the line last week. So now the drawing code is
translate(width/2, height/2)
background(0)
fill(255)
noStroke()
circle(0, 0, 10) // Draw the center circle (filled), just for reference
noFill();
stroke(255)
let n = 7 // Number of rings and dots
let angle = TWO_PI // Angle to draw dots at
let r = 0
for (let i = 0; i < n; i++) {
r = width/15 + i*4*width/(10*n) // Radius of each ring
arc(0, 0, 2*r, 2*r, PI, TWO_PI); // Draw the ring
circle(cos(angle) * r, sin(angle) * r, 10) // Draw the outer dots (outlined)
}
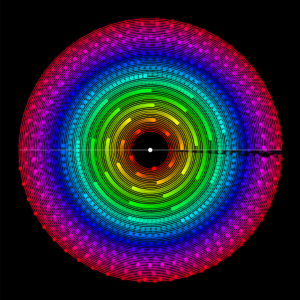
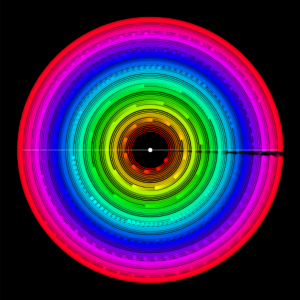
And we get:
And we got a pretty close structure already!
I then played around with the spacing a bit, and ended up using a different equation altogether (same concept and method as original, but I didn’t condense it).
Now, I changed the arcs to be nearly full circles instead (wasn’t sure yet, so you’ll see a lot of screenshots with a gap in the right side, that was intentional to help me note something). Also, now that I had some of the basics of the project down, I switched to using Object Oriented Programming, and made a class for the rings and another for the dots, as well as added a simple line to the center of the screen. I could then animate the dots across the screen by changing their angle. Now, instead of assigning them all the same angle (which would result in a straight line of dots traveling along a circle), I made each dot have a different velocity, and then incremented their angle by that velocity, giving us staggered dots!
The first hints of a spiral (and changed the spacing again)Changed the spacing yet again.
The cool thing about the velocity, is that I calculated in such a way that I could control exactly when all the dots came back together again (which is just incredibly cool to see and hear).
Now, I wanted to highlight the ring whose dot has touched the line. I first just tried checking whether the dot’s y position was zero, but that didn’t really work, because a dot could easily skip past it based on it’s velocity and starting angle (and in fact, often did). This was a similar issue with using the angle instead. I then gave a bit of margin (so instead of checking whether angle == 2 Π, I checked whether the difference was less than a certain amount. This seemed to work! (ring highlighted in red, for now, and oh, I also added a trail effect, by doing background(0, 8), a trick I love using).
But unfortunately, not really… It spammed a lot.
Wayy too many collisions for a few dots…
I could try adjusting the tolerance/margin, but I knew that was a losing battle (as the lower it is, the fewer false triggers I’ll receive, but also the fewer actual triggers, due to missing it, and vice versa).
So then, I came up with a new method. I would calculate the dot’s position before, now, and after one iteration, and check to see when it was closest to the line. If it was closest to the line now, and was further away before, and would be further away later, then this meant we could trigger the collision. It looked something like this:
class Dot {
// ...
hasCollided() {
let differenceBefore = abs(sin(this.angle - this.velocity));
let differenceNow = abs(sin(this.angle));
let differenceAhead = abs(sin(this.angle + this.velocity));
// check if the dot is closest to the line
if (differenceNow < differenceBefore && differenceNow < differenceAhead) {
return true;
} else {
return false;
}
Aaand, it worked!
After that, I added colors to the rings. I wanted a solution that would dynamically scale with the number of dots, and so what I did was divided up hue (360 degrees) by the number of dots, and used that for the HSL colour (so, similar to the dot’s spacing, but for colour) (also, gosh, isn’t HSL so much better?). I added this line to the loop let ringColour = color(i * 360 / numRings, 100, 80) (and oh, changed the spacing to let radius = gap + (width/2 - 2*gap) * i/(numRings-1) 😅, which is much more understandable).
Yay, rainbow colours! (though there’s still the red highlight 🤦♂️)
Then I changed the highlight to the ring’s colour, and tried something out. I increased the ring amount to something much higher (I think 21), and got this cool result.
Oooooo
Refining it a bit more (changing the background call’s opacity), and we get an even more beautiful result! (though it’s hard to tell when the dots collide, as it’s now just a continuous line)
Ooooooooooo pretty!
## Sound & Additional Thoughts
Then, I wanted to add some sound (you know, like the MAIN reason I even wanted to make this?). This was a challenge (and took a good chunk of time). Not the actual code for the playing the sound, no that was relatively simple, as I just had to create a new PolySynth (since I wanted to play MIDI notes instead of manual hard coded files, to also scale with the number of rings) with polySynth = new p5.PolySynth(), and then played a sound every time a collision happened (with the sound being based on the ring’s index). No no, the hard part was choosing what sounds to play.
I noticed that p5’s PolySynth accepted MIDI names and notes, but whenever I tried using the numbers, it didn’t really sound as it was supposed to (according to the translation tables). So I created a new rough sketch and explored in there. So basically, MIDI notes first have a character (one A, A#, B, C, C#, D, D#, E, F, F#, G, G#) (though keep it mind it usually starts from C, I don’t why p5 choose to start from A, at least from what I heard), and then a number from 0-8. I eventually created a converter that takes a number and outputs a MIDI note (with the slight help of an AI, though just because I was too tired at this time), and, it worked! Or, worked? Or, well, idk.
Ok, so it worked as intended, but it didn’t really sound nice at all, and nothing like the original video (though to be fair, he is a proper skilled artist, but still). Changing around some of the note assignment did help (I then started the notes from A4 (since I realised that you can’t even hear the first few notes, and some sound pretty terrible, so I restricted the range), and went to every 2nd or 3th note instead), but it still didn’t really sound like how I wanted to. I also tried playing with reverb, etc, but I’m probably missing a key component (yea, who could’ve guessed that a good sounding composition probably has more than just playing some notes in ascending order 😅). I could also just upload some files manually and use those (eg. from Hyperplexed’s CodePen (he also made a great video on it), which would make it sound nice, but that wouldn’t scale with the number of rings, and also feels a bit like cheating (idk why I enjoy making things harder for myself 🤷♂️). Well, at least it looks nice… sometimes.
Unfortunately, that about wraps up all the time I had, so we’re gonna have to end it here. As usual, there’s a lot I couldn’t add (like being to drag a slider to control the rings, and click on them to add dots, which was like, the entire reason for decoupling the dots from the rings (making separate classes, etc), so all that work was for nothing…), and even more I couldn’t write on here (especially about the sound), but that’s it for today, and I’ll catchup you next time! (right? You will read my next posts too right? please? 🥺😅)
Anyways, then, after much ado (😂), I present, my Polyrythmic spiral!
# Final Result
Controls:
Umm… nothing. Just listen to the peaceful and serene music… (just kidding, its doesn’t sound very nice yet 🙁 ).
You could however, adjust the number of rings and the gap between them, by opening the sketch and changing the parameters (found at the top).
Technically, you could also change anything in the sketch, if you get into the code (you could even turn it into a something random, like a giraffe. I don’t know why you would, but you could).
At Eyeo2012, Casey Reas gave a pretty interesting talk, titled”Chance Operations”, where he went somewhat deep into the history of computer graphics, and how randomness was used, sometimes for effect, othertimes as a signal or act of rebellion (against the modern, clean/perfectionist work).
It inspired me to think deeper about how I currently do and potentially could use randomness in my work (ok, fine, also since it’s the writing prompt 😅). I think I would primarily use randomness, in order to create something that can be continually enjoyed. We humans get easily bored, and so don’t really enjoy watching the exact same thing over and over again, since it becomes too predictable and boring (idk about Bob though, he binge watches the same episodes again and again…). So, by adding a certain amount of randomness, we can consistently get a unique and interesting result, which is also incredibly helpful for animation and repeated viewings/interactions.
Minecraft, probably the most iconic poster child of random terrain generation. (Note: Shaders and Distant Horizons were used, taken from youtu.be/4ufUqLNX9oQ)
However, this does also prompt the question about how much randomness to use. Clearly, putting randomness in charge of too many aspects can completely break down the desired effect, and often simply results in gibberish. Therefore, I think the ideal amount of randomness would be one that allows the work to be unique and “alive”, but within its bounds, making the work coherent and interesting. The exact amount of randomness used then ultimately depends on the artist and their desired result, but in almost all cases, randomness is constrained in some way (eg. instead of picking a completely random colour, one of the components of HSL (hue, saturation or lightness) could be random, while controlling the other two, allowing for random, yet pleasing and consistent colours).
For my second week’s project, I was thinking about a simple project that embodied loops. Something, which would make someone think about loops, but not too directly obvious. Just thinking about loops, an action that keeps repeating, the first 2 ideas that popped into my head (after a grid of images) were those circle drawing toys (idk what they’re called 🤷♂️), and L-system trees (huh? but that’s recursive! So, we’ll save that for later 😉 ). I guess we’re doing the first one. Remember these toys?
A spirograph, aka, “fun-children’s-drawing-circle-toy”
Ohh, a spirograph! That’s what they’re called 😅. Anyways, yes, those things. They reminded me of a loop because the person carries out the action (moving their hand in a circular motion) again and again (although surprisingly, the result is mesmerising).
I wanted to build something similar, but a bit simpler (idk why, but while building this sketch, I initially felt like I was teaching someone about loops 😅).
# Implementation
Let’s start by first drawing 1 line on a circle. More specifically, the endpoints of the line should lie on the circumference of the circle. We can use the handy unit circle and basic trigonometry to find out that we can get the x and y position of a point, by just supplying an angle and radius/length. This might not seem like a better deal, after all, we’re getting 2 (possibly more confusing) variables, for 2 (simple) variables, however, it makes the maths mucchhhh simpler.
Unit circle (from Wikipedia)
As you can see, the formulas are: x = cos(angle) & y = sin(angle) (but note, that angle must usually be in radians, as p5.js’s default angle mode is radians).
translate(width/2, height/2)
a1 = radians(0)
a2 = radians(90)
r = 300
x1 = cos(a1) * r
y1 = sin(a1) * r
x2 = cos(a2) * r
y2 = sin(a2) * r
line(x1, y1, x2, y2)
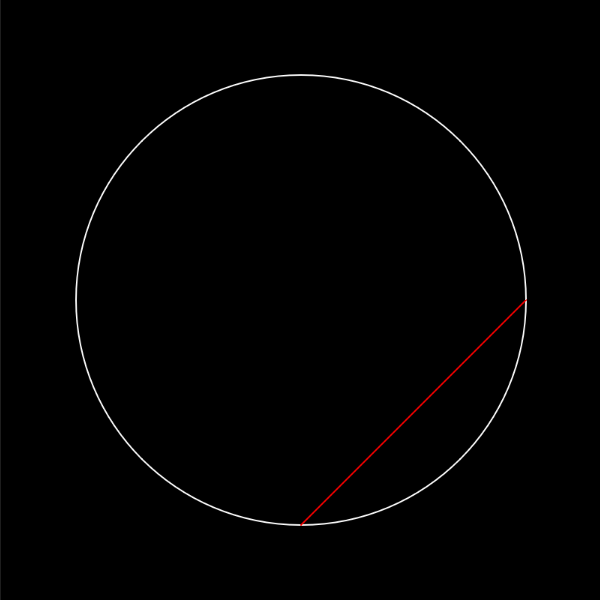
That gives us the following (I styled the background black, and the line red)
Ok, but how can we tell this is actually on a circle, and not just some random line? Let’s draw a circle outline and check (I used noFill() and stroke(255));
circle(0, 0, r)
Yep!
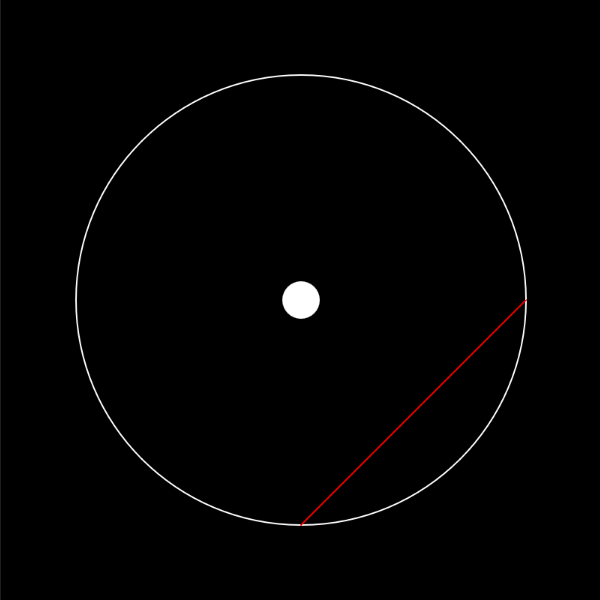
Yay! We can clearly see it’s on the line, and also control the angle! We can add a dot to the center, and also control the line using our mouse.
angle = frameCount/2000 + 1000.07 // Just a random nice looking starting point
num = 50
for (let i=0; i<num; i++) {
x1 = cos(angle * (i-1)) * r;
y1 = sin(angle * (i-1)) * r;
x2 = cos(angle * i) * r;
y2 = sin(angle * i) * r;
strokeWeight(1);
stroke(255, 0, 0, 255);
line(x1, y1, x2, y2);
}
Cool!
Oo, it’s already a bit mesmerising! (certainly enough for me to at least sit by and watch it for several minutes 😅). You’ll notice that the shape keeps changing, and this is due to the angle changing, which we did by tagging its value to number of frames that had passed since the sketch’s start frameCount (just be sure to slow it down a lot (eg. I used 2000), since there are usually 60 frames per second, so it’ll become too crazy!). Setting a variable based on the frame count like this is an incredibly helpful trick to animate the variables over time.
Another helpful trick is to be able to pause the sketch, which can sometimes help you to debug or understand your sketch better. We can achieve this by calling loop() and noLoop() respectively, based on isLooping()‘s output. It’s important to keep in mind that this stops our draw() function from running, so don’t try to restart the loop from within there! Instead, a better approach is to use a key press, which can be achieved like so:
I just used a ternary operator to make it shorter, but it corresponds to:
function keyPressed(event) {
if (event.key == "p") {
if (isLooping()) {
noLoop();
} else {
loop();
}
}
}
Now, it’s up to you on how you wanna style it, and what features you wanna add! For example, here’s how mine now looks like:
Cool, eh? Or nah?
The end.
…
## Drawing Context
Ok ok, fine, I’ll explain a bit, but just a BIT more. You see the cool glow effect? How did I do that? (well, I could just say the function I used, but that’s no fun, nor will you learn much).
p5.js exposes something called the rendering context, through a variable, aptly named (can you guess?)… drawingContext! (better luck next time). But what is that, and where does p5 get the value from?
The rendering context, in short, is basically what p5.js uses to actually draw the stuff on screen (part of the canvas API). For example, when write this:
strokeWeight(10);
noFill();
rect(x, y, w, h);
That might get executed as:
drawingContext.lineWidth = 10;
drawingContext.strokeRect(x, y, w, h);
Note: This is just a hypothetical example, and is probably not how p5.js actually works. For starters, drawingContext is exposed by them as you’ll read now.
And where does it get the value from? Well, it’s the “CanvasRenderingContext2D” (for the default 2D sketches), which it gets by calling .getContext('2d') on the canvas element.
“*Grumble grumble*, yada yada, why does this rendering wendering scherending context even matter?”
Well, firstly, rude, but secondly, good question. It’s because, while p5.js does provide easier functions for most things, it doesn’t expose everything that the rendering context has. Remember the glow effect from earlier? Well, it’s actually done through the .shadowBlur and .shadowColor properties, which aren’t exposed.
In addition to making it much easier to draw shadows/glows, there’s also a MUCH faster (hardware accelerated) blur function! (through the .filter property, which supports more than just blur.) This means we can finally use blur in our sketches, without our performance instantly tanking! (though it still has to be used with caution, as it’s still a heavy effect (similar to the shadows), so too much can still cause performance to drop.)
Also, we can easily make gradients! That’s right, linear, radial, conic, you name it, gradient! I’d recommend checking out these 3 videos to learn more:
For my circle, I added 3 layers of lines. The first one is red and has a stroke weight of 5, with a red glow. The next 2 don’t have any glow, and are blue (with a stroke weight of 4) and white (with a stroke weight of 2) respectively. I also changed a few things, like making it spawn and follow the user’s cursor, and the ability to change it’s size. It also reminded me of Dr. Strange’s “circle-magic-thingies” and similar, so I added another circle to lean into that.
So that’s mostly it! Anyways, without further ado, I present, the final result!
I really like how the end result looks like, especially the colours and glow, and how it animates (hope others find it cool too). Although, I wish I could implement some of my other ideas too (and make it look more like the circular spells you see), but unfortunately that’s all I have time for right now, so we’ll have to end it here. Until next time!
Goodbye! (from Shutterstock) (hehe, maybe I’m liking this neon style too much 😅)
I was wondering about what to create, since I wanted it to both be impressive, and interactive. I had several ideas:
1.
Initially, I thought about an intro sequence where a little square is formed out a material in a factory/assembly line like style, and then it falls into the right spot below, completing a picture (my stylised portrait). This sequence would only last maybe 5-10 seconds. Then, either a flying spaceship or TRON lightcycle would come breaking through the 2D picture, and then you could control it on a 3D grid (with the elevation generated with perlin noise). After the set time runs out, it would fade to a screen with the player model standing alongside the spaceship/lightcycle, and the path traced out by the player would be the emblem/symbol on the player’s shirt and also be animated below.
While this is a pretty cool idea, it didn’t exactly fit in. Not to mention, it seems wayy higher effort than even sensible for a first post (but that wasn’t my primary concern). Had I joined the course from the beginning, I might’ve done that, but with a 2 week late start, it wasn’t feasible.
2.
A sand game (like sandspiel / powder toy game), where my portrait is formed by the sand and similar particles falling from above. Then, you could control/play with it, adding and removing the sand, adding water, blowing the sand around, lighting fire, etc.
Sandspiel (it’s awesome!)
This was actually a pretty good idea, and I had even gone through a few different resources (Coding Train’s falling sand, jason.today’s blogs, etc). I could even put the rest of the action from the point above after this, if time permitted. Ultimately, idk why, but I wanted to do something in 3D, especially as I realised I wouldn’t have enough time to do the sequence I imagined in the first idea.
3.
So, a 3D sand game! This idea seemed perfect. My portrait could form like in the 2nd idea, and it would be incredibly interactive! I liked it a lot, and also saw many things on this (such as toad pond saga’s videos on it, and more), in fact, going into a deep dive on other voxel games. Unfortunately, what I also went into a deep dive on was performance, and I realised that I was going to need to manually code some major portions of it (like the rendering), if I wanted good performance, as p5.js’s built-in methods wouldn’t suffice (eg. I would need to dynamically build a single static mesh, cull faces using a binary greedy mesher or just a simple direction check if the camera was orthographic, GPU instancing, etc, etc, etc). In the end, despite how cool, and simply interactive it was, I had to give it up due to the amount of time it would take to optimise performance.
4.
Then (skipping a few over), this brings me to my current idea, the one I ultimately ended up going with. The dual perspective illusion. I wanted something that could represent a bit more meaning, and I found the “illusion” perfect for representing 2 different perspectives, while looking at the same object. There were 2 ways to do this, one using a classic object that many of you have probably seen before, and another, using a 3D model. I choose the latter.
Since I had to create a portrait, one of the sides had to be a portrait. The other one however was free for me to choose from. I initially thought about the text/logo of Intro to IM, and a few other things, but in the end settled on a lightbulb-heart combo, representing my love of innovation and creativity.
# Implementation
## Finding and Modifying Images
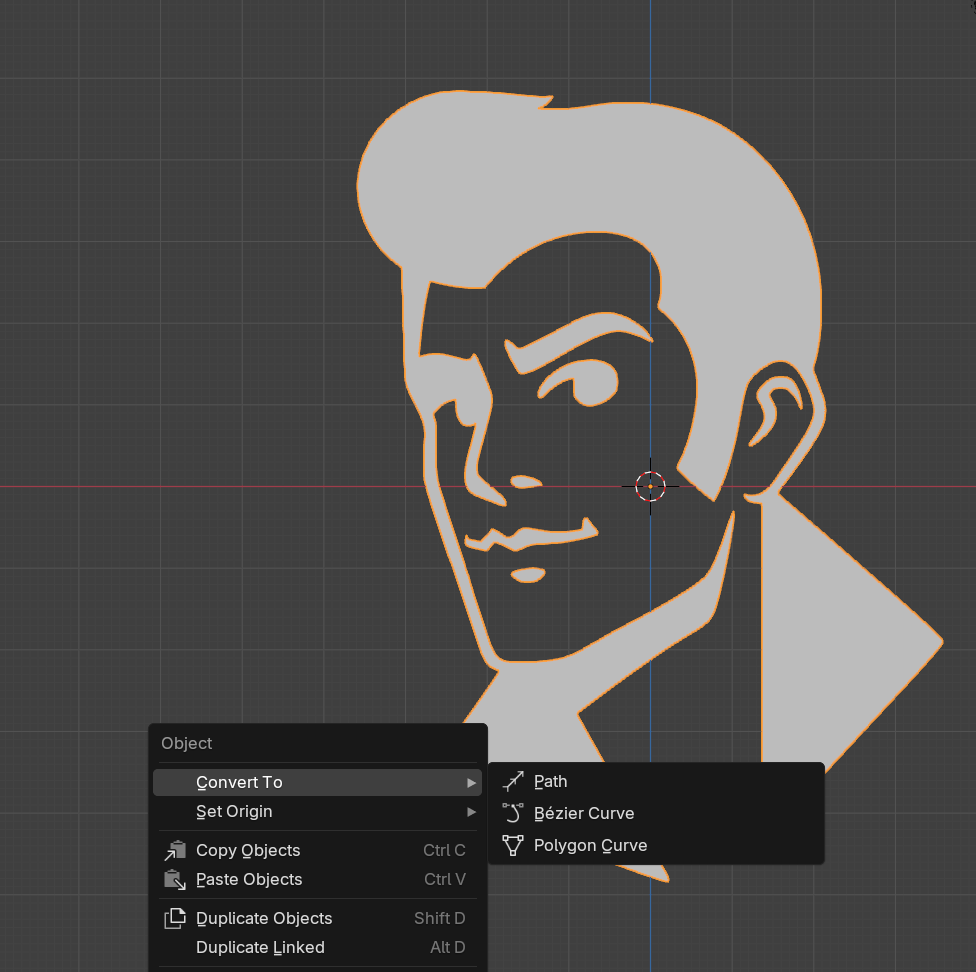
One way to create such a 3D model, is to take 2 flat surfaces (eg. images, flat models, text, etc), extrude them (add thickness), and then use a boolean intersection operation (this creates a shape only where the previous 2 intersected). There were 2 ways I could go about doing this. I could try and do them entirely using p5, but that would take a lot longer, since it wasn’t really built for this work. Or alternatively, I could use standard tools like a vector editor (in my case, I choose Inkscape) & a 3D editor (eg. Blender) to get it done much faster. Due to the aforementioned time constraints, I choose the later, but only since I knew that I could recreate this entirely in p5.js if I needed to, so I wasn’t “cheating”.
Now, the first thing I needed was a portrait, and a lightbulb-heart thingy. I thought about making them myself, but after browsing around for a while, I found a few images that were close to what I wanted.
Face (from alamy.com)Lightbulb-heart (from iconfinder.com)
I converted the face into a vector format, and then edited it to suit my liking more. For example, I cropped it, removed the holes, cleaned it up, and I obviously didn’t like that he had a cigarette, so I tried manually editing the vertices, which to be honest makes his mouth look a bit wonky 😅, but it’s workable.
I also did a similar thing with the lightbulb-heart thingy (gosh, I have to stop calling it that), and got this:
## Creating the 3D Model
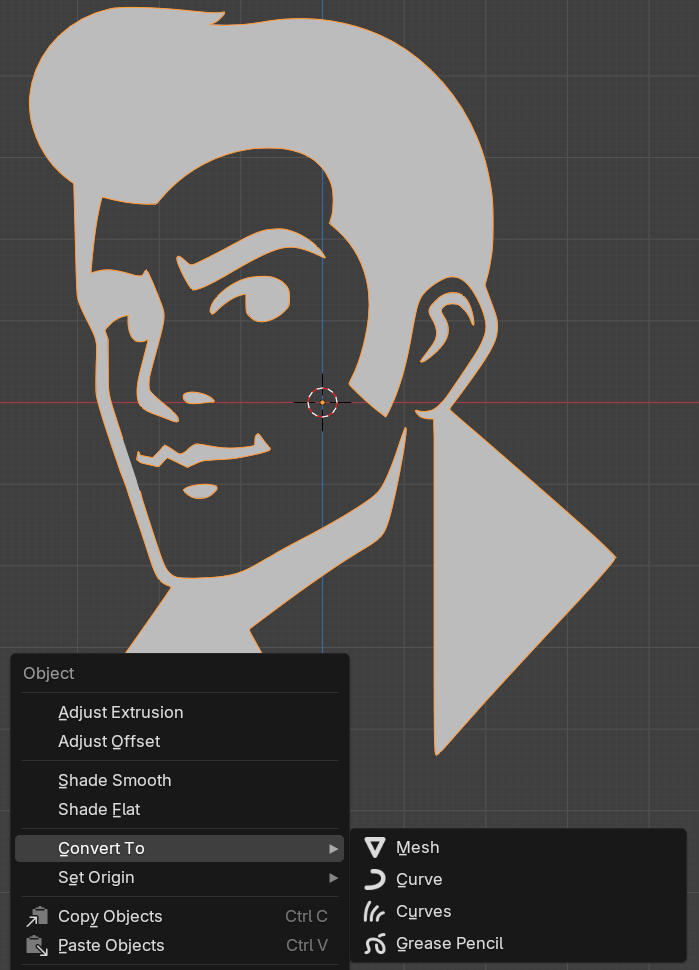
After this, I imported them into Blender, and oh, boy oh boy, this took up most of my time. For some reason, it was pretty hard to get the SVGs into the right format. When you import an SVG in Blender, it (in recent versions) gets converted into a Grease Pencil object (a type of 2D animation), but the format we need it in is a mesh (a 3D object). Unfortunately, there’s no direct route.
Why no mesh?!
Luckily, I found out that you could first convert it into a curve, and then into a mesh. Simple enough. The issue is, is that it didn’t work for me. I spent a long time struggling with this, until I realised that after I had converted it, I still had the original Grease Pencil object selected, as Blender had created a new curve object, instead of converting the existing one 🤦♂️. After I selected the right one though, it was finally there!
Finally!!
I won’t get into the specifics, but basically I cleaned it up again (to remove some vertices, as the lower the number, the smaller the filesize and loading time, something we’ll get back to) and extruded it (solidify). Then, I did a similar thing with the lightbulb-heart thingy (gosh), but this time made multiple copies, since I had to “poke holes” for the center floating heart to come through.
An anchor issue
There were a few more issues I had to fix, such some missing vertices for the hair, some of the elements being extruded to the wrong side (as seen above, probably due to the orientation of vertices (clockwise vs anticlockwise) or something), an incredibly annoying one about the face’s vertices not connecting (since I edited them, even though I definitely felt like I connected them), etc.
After resolving all that, I ended with proper model!
The model from an angleThe model (from straight, “head on” :D) Though an eye is nearly gone…The model from another straight side
The model appears garbled from other angles, but clearly forms a face or lightbulb from a particular angle. Isn’t that so cool?!
I then thought about adding a caption, which is also double sided, and followed this tutorial (which showed the same steps), resulting in:
The model, face sideThe model, lightbulb-heart side
I wanted to portray the double sided meaning, by expanding or peering into the mind of the person. I wish I could’ve chosen something much more creative, but since I lack anything close to representing an artistic ability, I settled with “Z ♥ Ideas” (since innovation or creativity felt too long to fit in there).
## Creating the Sketch
This brings me to the next challenge of trying to bring it into p5.js. Boy oh boy. *deep inhalation & exhalation*. The first, unexpected, challenge was trying to import it into p5.js. I didn’t expect this to become a challenge, but for some reason, I just could not upload anything to the website. In fact, the entire menu wasn’t functional! (yes, I tried rebooting, relogging, etc, multiple times across multiple days)
What are you for?? Decoration?!
The menu that did work, was the Sketch one, but that only allowed creating files and folders.
Well, at least this works…
No issue then, I thought I’ll just create a file named model.obj or something, and copy paste the entire contents of the file into it (since obj is a text based format).
p5.js’s file naming restrictions
*Sigh*. p5.js only allows us to create a file with a limited set of extensions. Fortunately, we can rename files and change the name (and extension) to anything, so yay!
I also tried hosting the files locally using a webserver and fetching them from the website (which somehow worked, code below), but alas, I didn’t find a way to save the files directly, so my option was to copy and paste from the console, which didn’t provide any benefit.
function setup() {
let models = [
"test 3.stl",
"test 0.obj",
"test 0.stl",
"test 1.obj",
"test 2.obj",
"test 3 (ASCII).stl",
"test 3.obj"
]
// Fetch the models from my computer and print them in the console
for (let modelName of models) {
fetch(`http://localhost:5500/models/${modelName}`)
.then(res => res.text())
.then(txt => print(`\n\nModel: ${modelName}\n`, txt))
// Then I would manually "Copy Object" of a response (eg. test 0.obj), create the file "test 0.obj.txt" (since only a few file extensions are allowed, and for some reason obj isn't on that list), then paste the contents, then rename the file to remove the ".txt".
}
}
(the code above also hints at multiple models, something I’ll revisit)
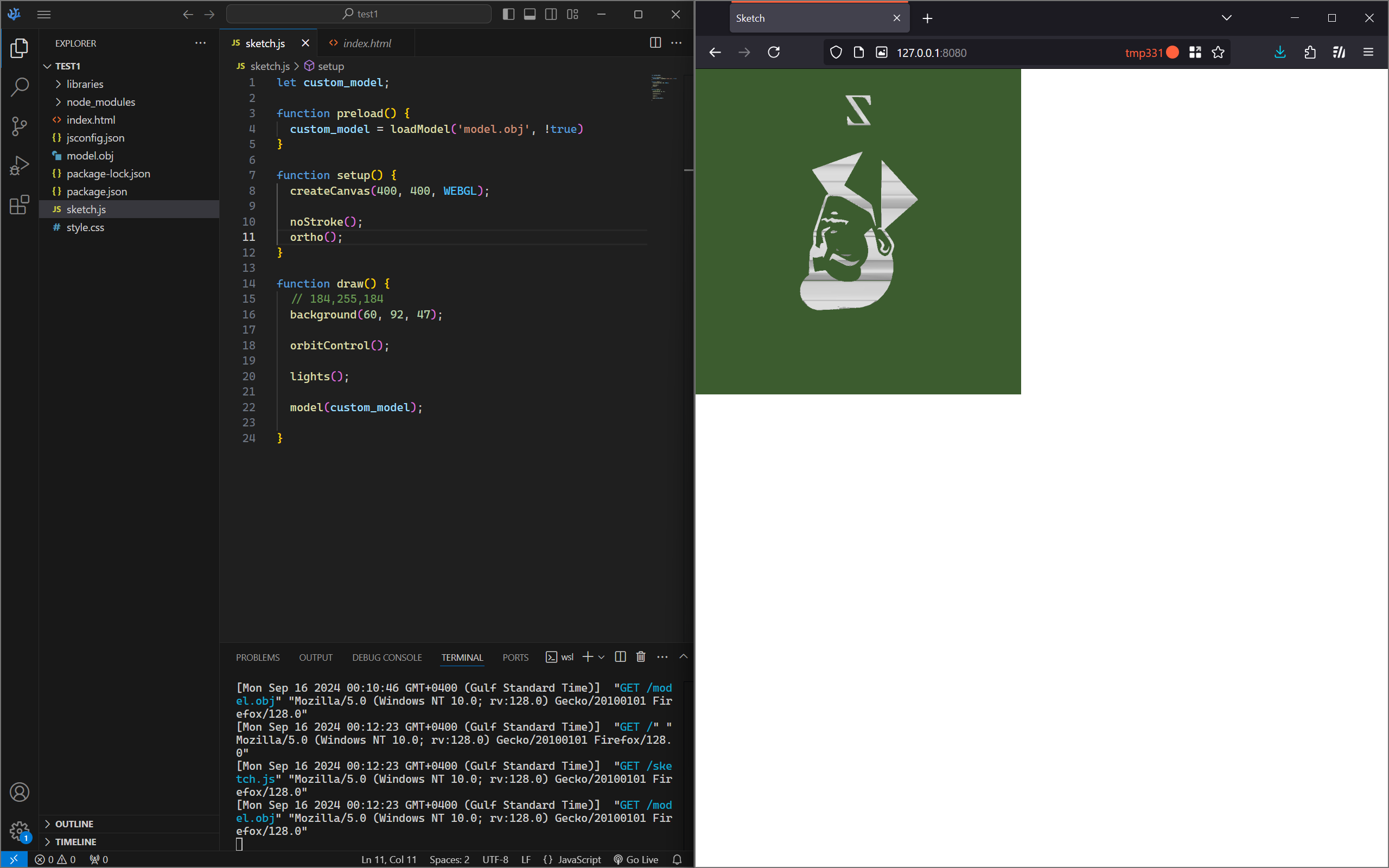
In fact, I actually gave up and continued on my local machine (using VS Code, with the p5.vscode extension, and npm http-server package, since I didn’t want the page constantly refreshing due to the model taking time to load), but I did later on manage to get the model on the website. After writing some quick code, I can see that… woops. The model isn’t the correct way around.
It’s upside down!
I was sort of expecting this, due to having a (very, very ) limited amount of experience with similar stuff. However, I did not expect how difficult it would be to get it the right way around!
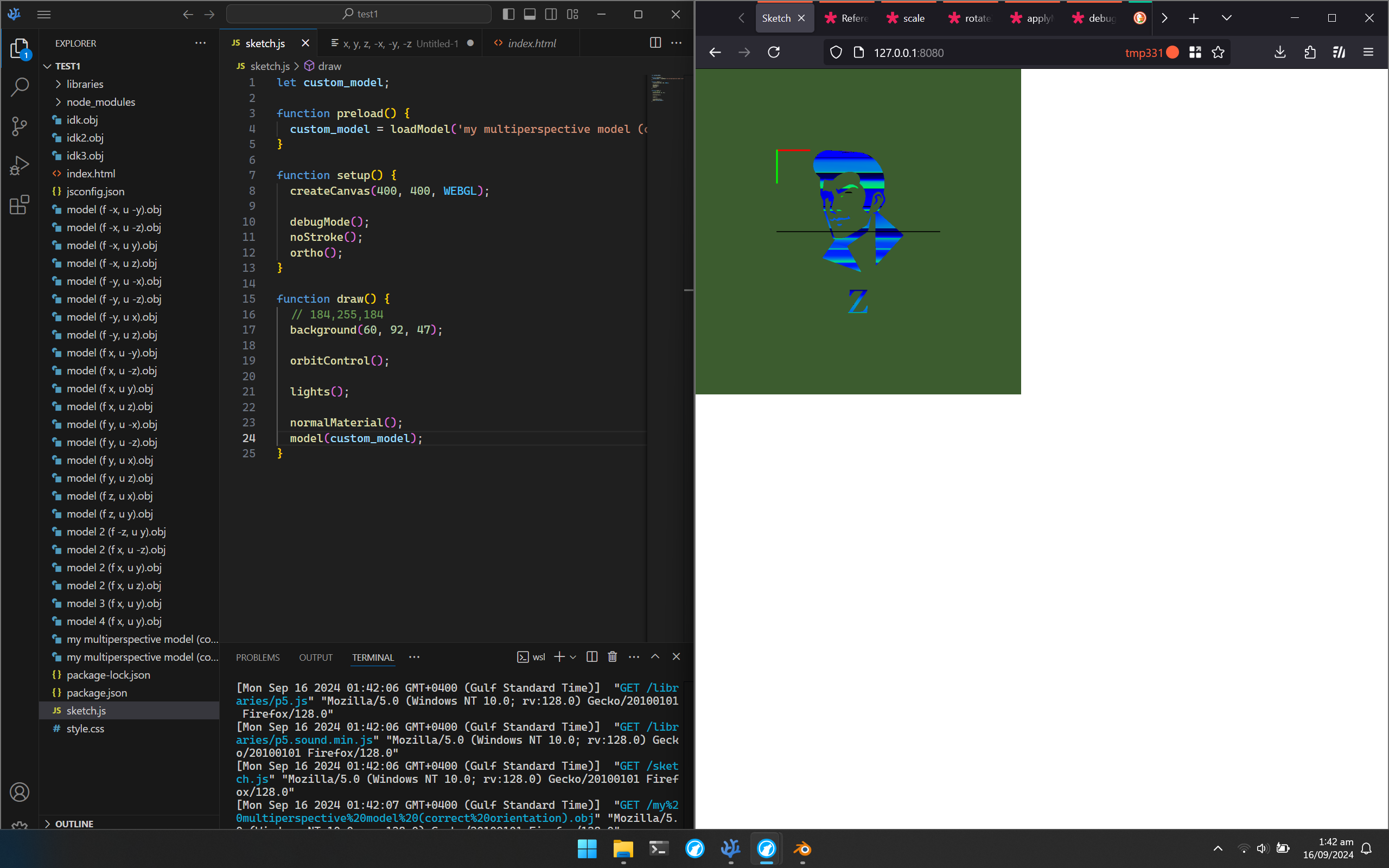
I nearly went mad, trying out over 36 different combinations of exporting the model. In short, none of them worked, so I ended up switching tactics, just sticking with one orientation, and modifying the model directly in Blender (you might be wondering why I didn’t just rotate it in p5.js, and while that certainly is an option (and in hindsight, maybe the smarter one due to saving time), that might have caused issues later on down the line, and didn’t feel as “correct” or “clean”). I tried many more times, and skipping over all that, I, FINALLY, got it working correctly.
FINALLY!
(the normal material was just to help with the orientation, though I don’t know if it actually did, or just made me more confused 😅. debugMode() was to provide the grid and axis indicator. Also, you can see some of the insanity in the small number of models shown here)
However, the model in Blender is now misaligned😅. Anyways, I got that done. Yay -_-.
### Testing performance
Now, I noticed that loading the model took a pretty long time, so I wanted to reduce the size of the model, in order to make the sketch load faster. I assumed it would, but I also wanted to test it (for some reason 🤷♂️).
To do so, I added the line:
let startTime = new Date();
And then added this as the first thing in setup() (since I loaded my model in preload(), which runs before setup()).
print(`Finished loading model in ${(new Date() - startTime)/1000} s`)
And these are the results I got:
Model
Time 1 (s)
Time 2 (s)
Time 3 (s)
Time 4 (s)
Time 5 (s)
Avg Time (s)
Avg Time, excluding extremes (s)
Original
10.167
6.850
17.533
28.484
1.783
12.963
6.910
Optimised 1
10.850
5.366
4.933
4.683
0.767
5.320
2.996
Optimised 2
2.533
4.133
16.083
0.850
0.750
4.870
1.503
Optimised 3
9.566
5.400
3.300
23.067
0.400
8.347
3.653
Basically, the more optimised it was, the lower the number of vertices it had, and the lower the file size. You would logically expect the most optimised one to load the quickest, but surprisingly, that wasn’t exactly the case. While it did have the shortest time, overall, the times are scattered all over the place, and wildly inconsistent (probably due to caching, traffic/load and server availability, etc), so a much, much larger number of samples are needed to determine anything with statistical significance. Regardless, I went with the most optimised one, just out of theory and kindness too (why put extra burden sending unnecessary bits), but it does unfortunately look the worst (due to having a lower resolution, but I hope the difference isn’t much).
### Brief Explanation of Some Code
Now, a brief explanation of some of the code.
I loaded the model using loadModel() (passing true as the second argument, normalises the model)
Then I initialised the first camera by doing the following
// Initialise camera, and point to the 1st side (face)
faceCam = createCamera();
faceCam.ortho();
faceCam.setPosition(0, 0, 800);
faceCam.lookAt(0, 1, 0)
.ortho() sets the camera to be orthographic, and .setPosition & .lookAt are self-explanatory, but they position the camera to point to the face. I set up the 2nd camera similarly, and then have a main camera.
I’m able to resize the canvas to the maximum size (while maintaining a square aspect ratio) by:
In the code above, I interpret the scale from 0 to 1, and Y rotation from 0 to 4Π, according to the elastic ease in and out, which I found from easings.net
Similar to lerp (which stands for linear interpolation), there’s also slerp (a special spherical version), which I use in a similar manner to smoothly transition the camera to the first and second sides when the user presses ‘1’ and ‘2’ respectively.
Lastly, I just draw the model
// Draw custom model
fill(64, 112, 112);
model(customModel);
That’s mostly it. Anyways, without further ado, I present, the final sketch!
# The Final Sketch
Controls:
Mouse drag: Orbit camera
Mouse scroll: Zoom
1: Face the face 😀
2: Face the light bulb
# Additional Thoughts
I had planned to also some nice rustling orange leaves and ambient music, alongside an option with the model on a 3D background, but that unfortunately had to be cut due to time (alongside a huge portion of what I wanted to tell on his blog).
Additionally, I would like to implement the orbital controls myself, so that I can properly restrain the camera from going too far or crossing (flipping) over, improving the user experience, as well as add buttons to switch to the 2 views (in addition to the current key shortcuts).
Also, I would’ve liked to actually move parts of the model, so that it could transition between different states.
I know you’re really enjoying reading such a long post, but fortunately or unfortunately, that’s all the time I’ve got, so we’ll have to end it here. Until next time!


 Code:
Code:














")





 : Move magic spell
: Move magic spell : Grow its size
: Grow its size