# Jump To:
# Introduction
Hey everyone! 👋
Like probably everyone else on the entire planet, I wasn’t really sure what to do for my Intro to IM Midterm Project at NYUAD (ok fine, maybe not everyone else) (fun fact, I’m still not certain 😂😭). I was deliberating whether to stick with traditional input devices (mouse and keyboard), or go for some interesting new (like the classic and probably cliche, face or body tracking). Unfortunately, I don’t own a guitar like Pi Ko, so I guess I’ll have to stick with something traditional 😅 (now that I think about it, I could use a piano, wait a moment…)
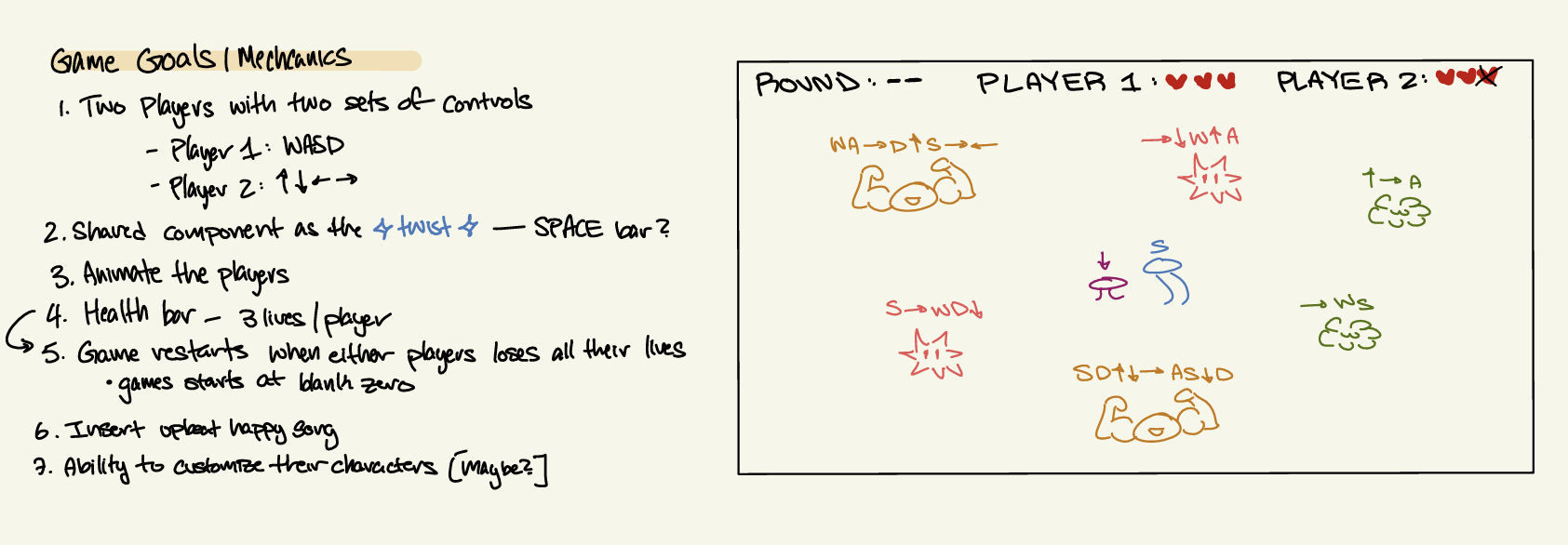
# Piano Game Concept
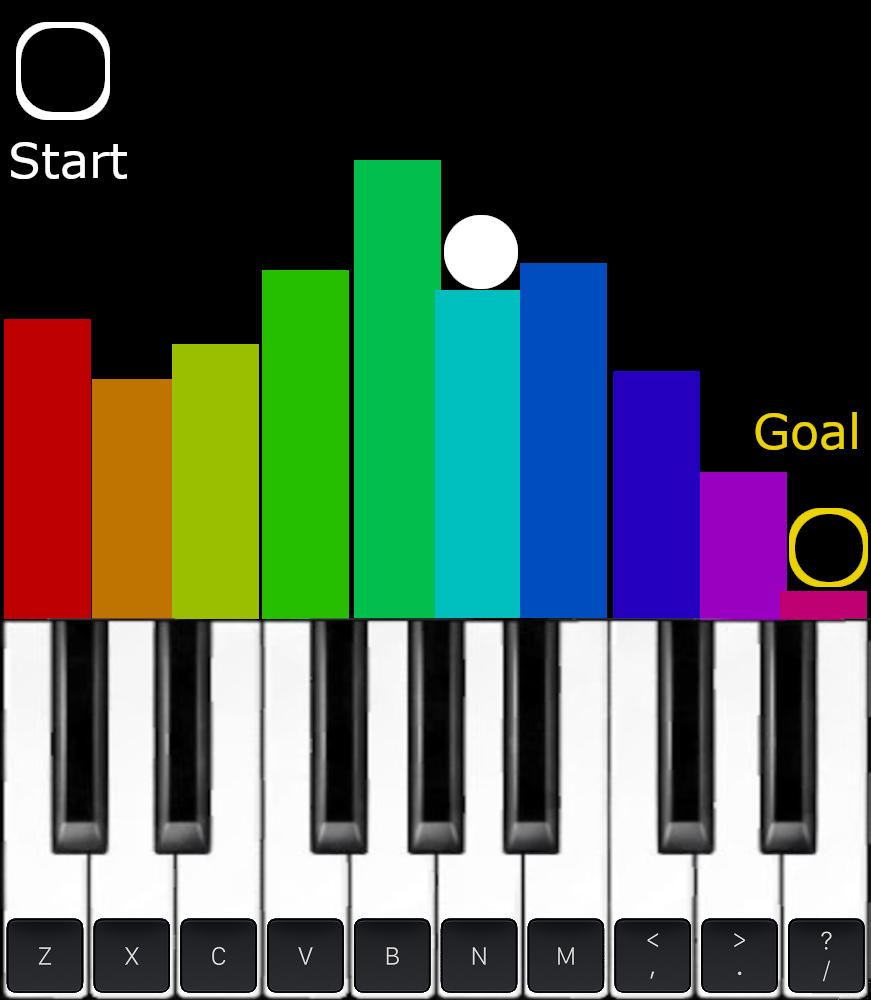
Gosh… why do I waste so much time, on a joke concept…
So the keys of the piano (but optionally also the keyboard, allowing everyone to play it) control the height of the bars, and you have to get a ball that drops out of the start area into the goal, potentially avoiding obstacles and overcoming bad physics, all the while automatically producing (probably ear piercing) music random garble of sounds. That’s a win-win-win!
Ok, this was a joke. Now back to the actual concept I wanted to talk about 😅 (though to be honest, this seems more original and fun ._.)
# Actual Game Concept
You know those outlines they have of people (like at crime scenes, but don’t think about that)?

Or those ones where a cartoon character goes through a wall?

Well, what if you had to make the correct pose to fit through a series of holes and avoid hitting the wall? That’s the essence of my idea. I thought about it while thinking on how I could utilise face/body tracking (which probably shows 😅), and which is exactly the wrong approach (you’re supposed to first have an issue/idea, then think about how to solve it, not try to find a use case for a certain techonology, that’s like a solution in search of a problem). Also, this idea is simple and obvious enough that while I haven’t seen it yet, it very well might already be a real thing. Still, I find the idea quite charming, especially as I envision it on a large screen, with people frantically and hilariously jumping around positions. I will also include a “laptop mode”, where the program only shows upper body cutouts, in order to make it accessible and playable on laptops too (where it would be hard to get the distance required for the camera to see the full body, while still allowing you to comfortably see the screen).
It should not come as a surprise then, that I plan to use body tracking to be able to control the motion of the character. Of course, it would be a gargantuan task to implement a decent body tracking solution from scratch (something more for a final year’s or even PhD’s research project than an Intro to IM midterm), so I will use a pre-existing library to handle the detection for me, mainly movenet (probably through ml5.js), a fast and accurate pose detection model by Google.
As I was thinking about this a bit, I began thinking that maybe this could be about a ninja’s training. You enter the secret facility (the interface is hopefully interactable through hand gestures, similar to the Xbox with kinect, if I have enough time), and then have to undergo the “lightning quick attack & defense poses” (or something), as part of your training.
## Complex part & Risk Reduction
As part of our midterm progress blog post, we have to identify the most complex/frightening part, and do something to tackle and reduce that risk. For this project, it is obviously the body tracking, so I created a new sketch to test out the library, and coded together a simple barebones concept to ensure the tracking works, and if I can reliably assess whether a person is in the correct pose. In addition to the pose detection, it also displays a skeleton of the person (of the detected points), and I made it slightly show the webcam’s video feed (both to help the player adjust their position). Also, it shows a (faint) guide to the target pose.
 Mini rant:
Mini rant:
I first made an image for the target pose, but I’m still somehow unable to upload anything to p5, despite trying with different browsers, at different times, and even different accounts, since the start of the semester (yep, I haven’t been able to upload anything at all). Luckily in this case, it was just a simple image, so I drew it manually with p5.js (which is better in fact, since the image automatically updates if I change the target pose), but still, this is extremely annoying and limiting. If you know any solutions, please let me know.
Try and see if you can match the pose!
(Hint: It tests for the shoulders, elbows, and wrists. Also, try moving back and forth if the frame doesn’t fit, and try changing the lighting if it isn’t detecting you properly (ignore the flickering, that’s a known issue))
It works! Something I don’t like is the constant flickering, but I think I might be able to mostly solve that (at the expense of slower update times, by using a moving/sliding average), so I would consider this a success!